概要
本文讲解了如何使用 XML Web 控件获取远程XML数据并在 ASP.NET 页面显示这些XML数据,以及使用Repeater控件发布数据库中的XML数据。在过去的几年间,随着 异构平台间共享数据的需求不断增长,XML的使用也呈爆炸性增长。意识到这种趋势,微软在整个.NET框架中对 XML 提供了健壮的支持。这意味着,对于 ASP.NET 开发者来说,在Web页面 中显示和处理 XML 数据从来没有这么容易过。本文将通过生成一个 RSS2.0 聚合引擎和在线新闻聚合器来学习 XML 和 ASP.NET 技术。 本文假设读者熟悉 ASP.NET 和 XML。
简介
随着办公室和家庭上网在线时间的延长,以及 Web 站点和可访问的互联网应用程序呈持续爆炸性增长,应用程序之间能数据共享变得越来越重要。在 异构平台之间共享数据需要一种平台中立的数据格式,这种数据格式要求能易于通过标准的互联网协议来传输,而这正是XML的用武之地。因为XML文件本质上 只是一个文本文件,其编码格式众所周知,而且现有的XML解析器能为所有主流编程语言所用,所以XML数据能被任何平台轻松使用。
Web 网站聚合就是一种使用 XML 来共享数据的范例,在新闻站点和网志中经常可以看到。采用 Web 网站聚合技术,网站能以 XML 格式的 Web 可访问的聚合文件来发布最新内容。网站使用 的聚合格式有很多种,其中最流行的一种格式就是 RSS2.0。( RSS2.0 规范被发布在 Harvard Law 网站 的技术栏目上)。此外,MSDN 杂志有一个聚合文件:MSDN杂志:本期刊物, 其中列出了最新一期 MSDN 杂志上的文章,包括到在线版本文章的链接。
一旦 Web 站点有了公开发布聚合文件,那么不同的客户端就可以消费它。消费聚合文件的方式有很多种,比如,某个提供 .NET 技术资源的站点可能希望在网站中 添加最新的 MSDN 杂志文章标题。聚合文件还常常被新闻聚合器程序所用,这种程序被专门设计用来获取和显示不同来源的聚合文件。
随着人们越来越注重使用 XML 数据,在 ASP.NET 页面中处理 XML 数据的能力变得比以往更关键。既然 Web 站点聚合如此重要, 本文我们就来创建一个 Web 站点聚合文件生成程序和一个在线新闻聚合器。在建立这两个微型程序的过程中,我们将讲述如何访问和显示XML数据,不论这些数据是来自远端的Web服务器还是本地的文件系统。我们将演示如 何多种不同的方法显示XML数据,比如:用 Repeater 控件以及用 ASP.NET XML Web控件。
使用 RSS 2.0 规范的聚合内容
本文我们将要创建的第一个微型程序是一个聚合文件生成器。针对这个迷你程序,假设你是一个大型新闻网站(如 MSNBC.com)的 Web 开发者,所有的新闻内容都保存在 Microsoft SQL Server 2000 数据库中。具体地说,这些文章是 都保存在一个名为 Articles 的表中,表中以下字段与我们的程序密切相关:
·ArticleID—主键,自增长的整型字段,用来唯一标识每一篇文章;
·Title— 指定标题,字段数据类型: varchar(50);
·Author—指定作者,字段数据类型: varchar(50);
·Description—新闻内容描述,字段数据类型: varchar(2000);
·DatePublished—新闻发布日期,字段数据类型:datetime
请注意,Articles 表中可能还有其它字段,上面所列的只是我们在创建聚合文件的时候所要用到的字段。而且,这只是一个非常简单的数据模型,在 是应用的数据库环境中,你可能会使用更加标准化的数据库模型,比如具备一个单独的 authors (作者)表,有一个建立作者和文章之间多对多关系的表等等。
下一步,我们将创建一个ASP.NET页面,用格式化好的 RSS2.0 XML 文件显示一个最新的新闻列表。在讲述如何在 ASP.NET 页面 中完成这种转换之前,我们要先介绍一下 RSS2.0 规范的内容。我们应该记住,在整个规范中,RSS 是被设计用来为聚合内容提供一个数据模型。那么 毫无疑问,它会有一系列的 XML 元素,用来描述 Web 站点要聚合的内容信息,以及一系列用来描述某一特定新闻项的 XML 元素。最后,不要忘记 RSS 聚合文件是一个 XML 格式文件,必须符合 XML 格式化的准则, 也就是:
·所有 XML元素必须正确嵌套;
·所有的属性值要用引号包含起来;
·<, >, &, "和’’符号要相应地替换为 <,>, &, " 和 ';
而且,XML格式是大小写敏感的,这就意味着,XML元素的起始和终止标签必须匹配,拼写和大小写都必须一致。
RSS2.0 的根元素是<rss>元素,这个元素可以有一个版本号的属性,例如:
<rss version="2.0">
...
</rss>
<rss>元素只有一个子元素<channel>,用来描述聚合的内容。在<channel>元素里面有三个必需的子元素,用来描述 Web 站点的信息。这三个元素是:
·title—定义聚合文件的名称,一般来说,还会包括Web站点的名称;
·link—Web站点的URL;
·description—Web站点的一段简短的描述。
除此之外,还有一些可选元素来描述站点信息。这些元素的更多信息请参见 RSS2.0规范。
每一个新闻项目放在一个单独的<item>元素中。<channel>元素可以有任意数量的<item>元素。每个<item>元素可以有多种的子元素,唯一的要求是最少必须包含<title>元素和<description>元素其中一个作为子元素。以下列出了一些相关的<item> 子元素:
·title—新闻项目的标题;
·link—新闻项目的URL;
·description—新闻项目的大纲;
·author—新闻项目的作者;
·pubDate—新闻项目的发布日期
下面是一个非常简单的 RSS2.0 聚合文件。你可以从 RSS generated by Radio UserLand 看到其他的RSS2.0文件的例子。
<rss version="2.0">
<channel>
<title>Latest DataWebControls.com FAQs</title>
<link>http://datawebcontrols.com</link>
<description>
This is the syndication feed for the FAQs
at DataWebControls.com
</description>
<item>
<title>Working with the DataGrid</title>
<link>http://datawebcontrols.com/faqs/DataGrid.aspx</link>
<pubDate>Mon, 07 Jul 2003 21:00:00 GMT</pubDate>
</item>
<item>
<title>Working with the Repeater</title>
<description>
This article examines how to work with the Repeater
control.
</description>
<link>http://datawebcontrols.com/faqs/Repeater.aspx</link>
<pubDate>Tue 08 Jul 2003 12:00:00 GMT</pubDate>
</item>
</channel>
</rss>
关于<pubDate>元素的格式有一点特别重要,再此要讲一下。RSS 要求日期必须按照 RFC822 日期和时间规范 进行格式化,此格式要求:开头是一个可选的3字母星期缩写加一个逗号,接着必须是日加上3字母缩写的月份和年份,最后是一个带时区名的时间。另外,要注意 <description> 子元素是可选的:上 述文件第一个新闻没有 <description> 元素,而第二个新闻就有一个。
通过 ASP.NET 页面输出聚合内容
现在,我们已经知道了如何按照 RSS2.0 规范存储我们的新闻项,我们已经就绪创建一个 ASP.NET 页面,当用户发出请求时,就会返回网站聚合 的内容。更确切地说,我们将建立一个名字叫 rss.aspx 的 ASP.NET 页面,这个页面会按照 RSS2.0 规范的格式返回 Articles 数据库表中的最新的 5 个新闻项 。
可以有几种方法来完成这件事,稍后将会讲到。但是现在,我们首先要完成一件事,那就是先要从数据库中获得最新的5个新闻项。这可以用下面的 SQL 查询语句获得:
SELECT TOP 5 ArticleID,Title,Author,Description,DatePublished FROM Articles ORDER BY DatePublished DESC
获得了这些信息以后,我们需要把这些信息转换成相应的 RSS2.0 格式聚合文件。要把数据库的数据显示为XML数据最简单、快速的方法就是使用 Repeater 控件。准确地说,Repeater 控件 将在 HeaderTemplate 和 FooterTemplate 模版里显示<rss>元素、<channel>元素以及站点相关的 元素标签,在 ItemTemplate 模版里面显示 <item> 元素。下面是我们这个 ASP.NET 页面(.aspx文件)的 HTML 部分 :
<%@ Page language="c#" ContentType="text/xml" Codebehind="rss.aspx.cs"
AutoEventWireup="false" Inherits="SyndicationDemo.rss" %>
<asp:Repeater id="rptRSS" runat="server">
<HeaderTemplate>
<rss version="2.0">
<channel>
<title>ASP.NET News!</title>
<link>http://www.ASPNETNews.com/Headlines/</link>
<description>
This is the syndication feed for ASPNETNews.com.
</description>
</HeaderTemplate>
<ItemTemplate>
<item>
<title><%# FormatForXML(DataBinder.Eval(Container.DataItem,
"Title")) %></title>
<description>
<%# FormatForXML(DataBinder.Eval(Container.DataItem,
"Description")) %>
</description>
<link>
http://www.ASPNETNews.com/Story.aspx?ID=<%#
DataBinder.Eval(Container.DataItem, "ArticleID") %>
</link>
<author><%# FormatForXML(DataBinder.Eval(Container.DataItem,
"Author")) %></author>
<pubDate>
<%# String.Format("{0:R}",
DataBinder.Eval(Container.DataItem,
"DatePublished")) %>
</pubDate>
</item>
</ItemTemplate>
<FooterTemplate>
</channel>
</rss>
</FooterTemplate>
</asp:Repeater>
首先要注意的是:上面这段代码例子只包括 Repeater 控件,没有其它的 HTML 标记或 Web 控件。这是因为我们希望页面只输出 XML 格式的数据。实际上,观察一下 @Page 指令,你就会发现 ContentType 被设置为XML MIME 类型(text/xml)。其次要注意的是:在 ItemTemplate 模版里,当 在 XML 输出中添加数据库字段Title、Description 和 Author 时,我们调用了辅助函数 FormatForXML()。我们 很快就会看到,该函数被定义在后台编码的类中,其作用只是将非法的 xml 字符替换为它们对应的合法的转义字符。最后我们应该注意,在 <pubDate> 元素里面的数据库字段 DatePublished 是用 String.Format 来格式化的。标准的格式描述符“R”对 DatePublished 的值进行相应的格式化 。
此 Web 页面的后台编码类代码并不复杂。Page_Load 事件处理函数只是将数据库查询结果绑定到 Repeater控件,FormatForXML()函数根据需要做一些简单的字符串替换。为 简单起见,下面的例子只列出了这两个函数的代码:
在浏览器中访问 rss.aspx 页面的截图参见图一。
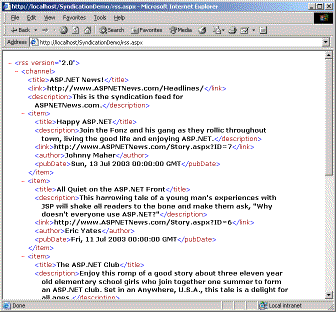
图一 通过浏览器访问 Rss.aspx 页面
在我们生成在线新闻聚合器之前,让我谈谈这个聚合引擎一些可能的增强功能。首先,每一次访问 rss.aspx 页面的时候,都要访问一次数据库。如果预期可能有大量的人频繁地访问 rss.aspx 页面,使用输出缓存是很有价值的。其次,通常新闻网站会将聚合的内容分为不同的类别。例如:News.com 有一些专门的聚合内容区, 比如针对企业计算、电子商务、通信的内容等等。在数据库表 Articles 中加入表示类别的 Category 字段就可以很容易地提供这种支持。这样 一来,在 rss.aspx 页面中,可以接收一个表示显示分类的查询参数,然后只搜索指定的新闻项分类即可。
在 ASP.NET 页面中使用聚合摘要
为了测试我们刚建立的聚合引擎,我们将创建一个在线新闻聚合器,允许采集任意数量的聚合内容摘要。聚合器的界面很简单,参见图二。它包括三个框架页面。左边框架以列表形式列出了不同的聚合内容摘要。右上部框架显示所选的聚合内容摘要包含的新闻项以及查看该新闻项的链接。最后,在右下部框架则显示选中的新闻项标题和内容。顺便提及一下,这样的界面基本上是各种类型的聚合器的一个事实上的标准界面,包括新闻聚合器、email客户端软件和新闻组阅读器都是这样的界面。
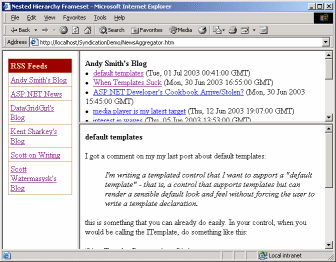
图二 新闻聚合器用户界面的截图
第一步是创建一个html页面来建立框架用户界面。幸运的是,在Visual Studio.NET 2003 中,这一过程非常容易。只需要在Web应用程序解决方案中添加一个新 的项目,选择新项目类型为 Frameset。(我在我的工程中将这个新文件命名为 NewsAggregator.htm。我之所以将它设置为 html 文件而不是 asp.net 页面, 是因为这个页面只包括建立框架的 html 代码。每一个单独的框架会显示一个 asp.net 页面)。下一步,参见图三,Frameset 模版向导会启动,简单地选择选项“Nested Hierarchy”,然后按ok按钮就可以了。
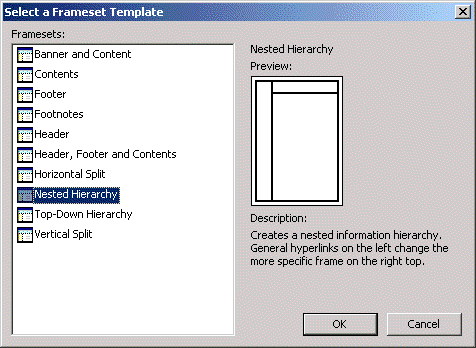
图三 VS2003 中 Frameset 模版向导画面
然后 Frameset 模版向导会创建一个HTML页面,里面已经加入了框架的源代码。 只要将左边框架的src属性设置为 DisplayFeeds.aspx,它是列表显示聚合摘要 asp.net 页面的 url。至此 NewsAggreator.htm 页面就完成了。
以下三个部分,我们将讲述如何创建在线新闻聚合器的三个组件,它们分别是显示聚合摘要列表的 DisplayFeeds.aspx;显示特定聚合摘要新闻项 的 DisplayNewsItems.aspx;以及显示指定聚合摘要特定新闻项具体内容的 DisplayItem.aspx。
显示聚合摘要列表
现在我们需要创建 DisplayFeeds.aspx 页面。该页面要显示订阅的聚合摘要列表。作为示范,我将这些聚合摘要放在一个叫 Feeds 的数据库表中。当然你也可以将它们放在一个XML文件中。表 Feeds 有如下四个字段:
·FeedID—主键,自增长整数类型,唯一标示一个摘要
·Title—摘要名称,数据库字段类型:varchar(50)
·URL—RSS 摘要的 URL,数据库字段类型:varchar(150)
·UpdateInterval—摘要更新频率(分钟),数据库字段类型:int
DisplayFeeds.aspx 页面使用一个 DataGrid 控件显示聚合摘要的列表。这个 DataGrid 只有一个 HyperLinkColumn 列,显示 Title 字段的内容并且链接到 DisplayNewsItems.aspx 页面, 在查询字符串中 要传递 FeedID 字段的值。以下是 DataGrid 控件的声明,为简单起见,省略了一些无关的部分):
<asp:DataGrid id="dgFeeds" runat="server"
AutoGenerateColumns="False" ...>
...
<Columns>
<asp:HyperLinkColumn Target="rtop"
DataNavigateUrlField="FeedID"
DataNavigateUrlFormatString="DisplayNewsItems.aspx?FeedID={0}"
DataTextField="Title" HeaderText="RSS Feeds">
</asp:HyperLinkColumn>
</Columns>
</asp:DataGrid>
这里要注意的关键是 HyperLinkColumn 列的定义。它的 Target 属性设置为右上部分框架的名称,这样当用户点击的时候,DisplayNewsItems.aspx 页面就会显示在右上部分的框架中。另外, 属性 DataNavigateUrlField、DataNavigateUrlFormatString 和 DataTextField 也做了相应的设置, 以便超链接显示摘要的标题,并且当点击它时,就会将用户带到 DisplayNewsItems.aspx 页面,并在查询串中将 FeedID 字段的内容传 过来。(该页面的后台代码类只访问来自 Feeds 表的摘要清单,按照 Title 字段的字母顺序返回,接着将查询结果绑定到 DataGrid 控件。 由于篇幅所限,本文在此不列出代码。)
显示特定聚合摘要的新闻项
我们面临的下一个任务是创建 DisplayNewsItems.aspx 页面。这个页面会以链接的形式显示所选聚合摘要的新闻项标题,当点击标题时,新闻的内容就会显示在右下部分的框架中。要完成这一任务,我们会面临以下两个主要的挑战:
·通过指定的 URL 访问 RSS 聚合摘要;
·将接收到的 XML 数据转换为相应的 HTML;
幸运的是,在.NET 框架中,要实现这两个任务都不是很难。对于第一个任务,只需要两行代码,我们就可以将远程的xml数据装载到一个XmlDocument对象中。而第二个任务呢, 借助 ASP.NET XML Web 控件在ASP.NET 页面中显示XML数据也比较容易。
XML Web 控件被设计用于在 Web 页面中显示原始或者转换过的 XML 数据。使用 XML Web 控件的第一步是定义XML数据源,通过 定义一系列的属性,用许多方法都可以完成这一工作。使用 Document属性,你可以指定一个 XmlDocument 实例作为 XML Web 控件的 XML 数据源。如果XML数据存在于 Web 服务器文件系统的一个文件中,可以用 DocumentSource 属性,只要提供该 XML 文件的相对或者绝对路径就可以了。最后,如果你 的 XML数据是一个字符串,那么你可以将这个字符串的内容赋给控件的 DocumentContent 属性。这三种办法都可以将 XML 数据与 XML 控件联系起来。
通常,在将 XML 数据显示到 Web 页面之前,我们会以某种方式转换 XML 数据。XML Web 控件允许我们指定一个 XSLT 样式表来做这个转换工作。与 XML 数据相似,XSLT 样式表可以通过 两个属性之一,以两种不同的方式中的一种来设置,一是 Transform 属性可被赋值给 XslTransform 实例,二是将本地 Web 服务器上 XSLT文件的 相对或绝对路径赋予 TransformSource 属性。
现在我们来创建 DisplayNewsItems.aspx 页面。在添加 XML Web 控件以及编写后台代码类之前,我们需要在 HTML 部分加入一小段客户端 JavaScript 代码。准确地说,是在 html 部分的 <head> 标签里面 添加如下的<script>代码块:
<script language="javascript">
// display a blank page in the bottom frame when the news items loads
parent.rbottom.location.href = "about:blank";
</script>
每当 DisplayNewsItems.aspx 页面装载的时候,这段客户端 JavaScript 代码会在右下角的框架中显示一个空白页。为了理解为什么要加入这段代码,我们来看看省略这段代码,我们会碰到什么情况:
·用户在左边的框架中点击聚合摘要,浏览器会在右上部的框架中装载摘要新闻项;
·用户在右上部框架中点击某个新闻项,浏览器会在右下部框架中装载这个新闻项 的详细内容;
现在用户在左边的框架中点击其它的聚合摘要,浏览器会在右上部分的框架中装载新的摘要新闻项;
前一个新闻项的详细内容还显示在右下部的框架中!通过上面的客户端 Javascript 代码,每次点击左面框架的摘要便可以清除右下部框架 的内容,以消除这一瑕疵。
在我们处理了客户端代码的问题之后,让我们把注意力转到添加 XML Web 控件。一旦加入 XML Web 控件,将其 ID 属性设置为 xsltNewsItems,TransformSourc 属性设置为 NewsItems.xslt(我们将要创建的 XSLT 样式表文件的名称)。现在,在 Page_Load 事件处理函数中,我们需要 在某个 XmlDocument 实例中获取远程 RSS 聚合文件,然后将该 XML Web 控件的 Document 属性赋给该 XmlDocument 实例。
在 Page_Load 事件处理函数中,与我们要实现的任务有密切关系的代码是最后三行代码。这三行代码创建一个新的 XmlDocument 对象, 加载远程 RSS 摘要内容,然后将这个 XmlDocument 对象赋给 XML Web 控件的 Document 属性。访问远程 XML 数据并 将它们显示在 ASP.NET 页面中就是这么简单,难道给你留下的印象不深吗?
剩下我们要做的一件事就是创建 XSLT 样式表,NewsItems.aspx。下面是样式表的第一版的草稿:
<?xml version="1.0" encoding="UTF-8" ?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" omit-xml-declaration="yes" />
<xsl:template match="/rss/channel">
<b><xsl:value-of select="title"
disable-output-escaping="yes" /></b>
<xsl:for-each select="item">
<li>
<a>
<xsl:attribute name="href">
DisplayItem.aspx?ID=<xsl:number value="position()" />
</xsl:attribute>
<xsl:attribute name="target">rbottom</xsl:attribute>
<xsl:value-of select="title"
disable-output-escaping="yes" />
</a>
(<xsl:value-of select="pubDate" />)
</li>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
这个XSLT样式表只有一个模版,用于匹配“/rss/channel”XPath表达式。这个模版先是以粗体显示<title>元素的内容。然后,循环获取每一个<item>元素,对于每一个元素,显示一个到 DisplayItem.aspx 页面的超链接,在查询字符串中传递<item>元素的位置属性。要留意超链接的 target 属性设置为 rbottom,右下部框架的名称。最后,显示每一个新闻项的标题和<pubDate>元素。
该 XSLT 样式表中有两个项目,并不是每个人都熟悉。首先是 <xsl:value-of> 元素中的 disable-output-escaping="yes" 属性。从本质上讲,这个属性的设置通知 XSLT 引擎不要转义那些非法的 XML 字符,比如:&, < , >, " 和 ’’。为了理解这个设置的意义,就要知道,如果不设置该属性(也就是设置为默认值"no"),那么如果标题包含一个转义的&字符&,那么输出的 html 文件中也会有一个&,而不单单是一个字符&。如果你再仔细想一想,你会发现这种情况会导致很多问题。例如,假设一个聚合文件的标题是“Matt’’s <i>Cool</i> Blog”,如果输出转义没有被禁止,那么输出就会保留 “Matt’’s <i>Cool</i> Blog”,在 Web 页面就会显示为 "Matt’’s <i>Cool</i> Blog"。当用 disable-output-escaping="yes"设置禁止输出转义时,输出就不会被转义,上面的内容就会被当作“Matt’’s <i>Cool</i> Blog”,显示在页面上就是我们想要的“Matt’’s Cool Blog”。
另一个要注意的是元素<a>。这个奇怪的语法会生成下面的输出内容:
<a href="DisplayItem.aspx?ID=position">news item title</a>
之所以要使用这种语法,是因为要给 XSLT 样式表中某个你要创建的元素添加一个属性,然后在该元素的标签里使用 <xsl:attribute> 语法 。有关该语法的一些例子可在 W3Schools 网站上找到:The <xsl:attribute> Element。
最后要注意的是,超链接的ID查询字符串的值是来自于 <xsl:number> 元素,从 position() 函数中返回的值。<xsl:number> 元素仅仅是输出一个数值。position()函数是一个 XPath 函数,用来返回 XML 文档中当前节点的顺序位置。这意味着对于第一个新闻项,position() 函数返回 1,第二个 新闻项,position函数返回 2,以此类推。我们需要记录这个值并将它通过查询字符串传递出去。这样当 DisplayItem.asp 页面被访问时,就可以知道显示 RSS 聚合摘要的什么项目了。
聪明的读者可能已经注意到,我们的 XSLT 样式表没有全部完成,因为 FeedID 参数没有通过查询字符串传递到 DisplayItem.aspx 页面。要明白 这是为什么,我们回顾一下在 ID 查询串参数中所传递的是用户拟察看详细信息的<item>元素顺序号。也就是说,如果用户点击第四条新闻项,页面 DisplayItem.aspx?ID=4 就会被 加载到右下部分的框架中。问题在于 DisplayItem.aspx 页面无法确定用户希望查看哪一个摘要。有两个不同的方法可以解决这个问题,比如可以在右下部框架中用客户端 Javascript 代码读取右上部框架的 URL,然后确定FeedID 的值。在我看来,更简单的办法是和 ID 参数一起将 FeedID 的值通过查询字符串传递 。
这样的话,有一个难题是 XSLT 样式表操纵的 RSS XML 数据中并没有 FeedID 值。但是 DisplayNewsItems.aspx 页面知道 FeedID 值,需要一种方法让 XSLT 样式表也知道这个值。通过使用 XSLT参数可以 实现完成。
XSLT 参数的使用是非常简单。在 XSLT 样式表中,你需要在 <xsl:template> 元素中加入一个<xsl:param> 元素, 该元素提供参数的名称。下面的代码将这个参数命名为 FeedID:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/rss/channel">
<xsl:param name="FeedID" />
...
</xsl:template>
</xsl:stylesheet>
现在,就可以用下面的语法在<xsl:value-of>元素中使用这个参数了:
<xsl:value-of select="$parameterName" />
最后,在我们的 XSLT 样式表中加入下面的代码,我们就可以把 FeedID 查询字符串参数加到超链接中了:
<a>
<xsl:attribute name="href">DisplayItem.aspx?ID=<xsl:number value="position()" />&FeedID=<xsl:value-of select="$FeedID"
/></xsl:attribute>
注意在ID查询字符串参数后面我们加了一个&字符(转义&),这样我们就可以传递 FeedID 参数的值到查询字符串的 FeedID 参数中了。 这就是我们要在 XSLT 样式表中添加的内容。
剩下的工作是在 DisplayNewsItems.aspx 页面的 Page_Load 事件处理函数中设置这个参数的值。通过使用 XsltArgumentList 类可以完成这一工作。这个类有一个 AddParameter() 方法。一旦我们创建了这个类的一个实例,加入了相应的参数,就可以将这个 实例赋给 XML Web 控件的 TransformArgumentList 参数了。下面的代码显示了更新后的 DisplayNewsItems.aspx 页面 Page_Load 事件处理函数:
显示特定新闻项的详细内容
还剩下最后一件需要做的事情是显示用户选择的特定新闻项的详细内容。这些详细内容将显示在右下部的框架中,而且将会显示新闻项的标题,描述和新闻项的链接等信息。和 DisplayNewsItem.aspx 页面 类似,DisplayItem.aspx 页面首先将根据传入的 FeedID 查询字符串参数获取远程的 RSS 聚合摘要,然后它会用 XML Web 控件显示这些详细内容。实际上,DisplayItem.aspx 页面的 Page_Load 事件处理函数和DisplayNewsItem.aspx 页面的 该函数几乎一样,只有以下两个小小的区别:
·DisplayItem.aspx 页面需要读取ID查询字符串参数的值;
·DisplayItem.aspx 页面使用一个 XSLT 参数,但是这个参数与 DisplayNewsItem.aspx 页面用的参数是不一样的;
DisplayNewsItem.aspx 和 DisplayItem.aspx 页面一样都需要在参数中传递一个 XSLT 样式表。DisplayNewsItem.aspx 页面传递的是 参数 FeedID,而 DisplayItem.aspx 还需要传入 ID 参数,它表示 XSLT 样式表应该显示那个新闻项。这个细小的差别在以下代码中以粗体显示,以下 代码省略了与 DisplayNewsItems.aspx 页面相同的部分:
以下是转换 XML 数据的 XSLT 样式表:
<?xml version="1.0" encoding="UTF-8" ?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" omit-xml-declaration="yes" />
<xsl:param name="ID" />
<xsl:template match="/rss/channel">
<b><xsl:value-of select="item[$ID]/title"
disable-output-escaping="yes" /></b>
<p>
<xsl:value-of select="item[$ID]/description"
disable-output-escaping="yes" />
</p>
<a>
<xsl:attribute name="href"><xsl:value-of
select="item[$ID]/link" /></xsl:attribute>
<xsl:attribute name="target">_blank</xsl:attribute>
Read More...
</a>
</xsl:template>
</xsl:stylesheet>
注意 <xsl:param> 元素被用于声明 ID XSLT 参数。然后,在几个不同的 <xsl:value-of> 元素中,ID 参数 被用来从 <item> 元素列表中抓取特定的 <item> 元素。在 XPath 的语法中,elementName[i]意思是根据相应元素名 存取第i个元素。例如,item[1]将只获取第一个<item>元素,item[2]则获取第二个元素。所以 item[$ID]是获取由 XSLT 参数 ID 定义的 特定 <item> 元素。
最后,值得注意的还有在样式表靠近末尾部分的超链接 Read More…,它的target属性设为空,这样的话当用户点击 Read More… 链接的时候,浏览器会打开一个新的窗口。
未来的扩展和当前程序的缺点
本文讲述的代码中有一个明显的缺点就是每次用户点击左边框架的某个聚合摘要或者在右上部框架点击某个新闻项时,远程聚合摘要都会被装载和解析。每次用户点击远程聚合 摘要时,所有的项都被加载,这样的效率无疑是很差的。每次用户点击一个新闻项标题就重新装载整个远程聚合摘要也是很浪费资源的。这样的方法不仅没有效率,对提供发布服务的个人或者公司也是不礼貌的,因为这些 连续的、不没必要的请求占用了他们的 Web 服务器的负载资源。
这个缺点在本文附带的源代码中已经得到解决。具体来说,.NET数据缓存可以用来存放不同摘要的 XmlDocument 对象。缓存间隔设置为数据表 Feeds 中 UpdateInterval 字段定义的值。(当然,由于某些原因,摘要的 XmlDocument 对象有可能会被提前清除出缓存)
这个系统的另外一个缺点是在右上部框架和右下部框架之间没有状态的保存。为了说明这样会引起什么问题,考虑以下的动作:
·用户点击左边框架的某个聚合摘要链接,在右上部框架中装载这个摘要的新闻项目。假设这个摘要的UpdateInterval 的值是30,则表示这些内容在30分钟之 后会过期;
·装载右上部框架的新闻项的同时,这些内容被缓存起来;
·用户离开去吃午饭;
·发布聚合内容的网站增加了一条新的新闻项;
·我们的用户一个小时午饭后回来了,这个 摘要的 XmlDocument 的缓存已经过期;
·用户点击右上部框架的第一条新闻项,将会在右下部分框架中装载 DisplayItem.aspx,传入 ID 参数值1;
·DisplayItem.aspx 页面在缓存中没找到 XmlDocument 对象,只好重新获取远程摘要。这样就会获得新的数据了(别忘了,步骤 4 已经加了一个新的新闻项),然后此页面会显示第一条新闻项目(因为ID参数的值为1) ;
·用户看到了新的新闻项,但是内容会令他感到有点困惑,因为已经不是他所点击的那一条新闻了,而且右上部也没有显示那条新的新闻。
之所以出现这样的问题,是因为 ID 参数没有唯一地标识一个新闻项,它只是一个特定时间点上新闻项列表中的一个偏移量。解决这个问题的一个好的方法是不要用数据缓存来保存聚合 摘要,而是使用数据库或者持久介质的其它方式(比如 Web 服务器本地文件系统的 XML 文件)。如果使用数据库,每一个新闻项都可以拥有一个唯一的标识号,可以用来传递到右下角的框架中。这种方法可以保证解决上面提到的问题。当然也会增加系统的复杂性,比如需要决定何时从数据库中清除掉旧的新闻项 。
本文现有的应用程序还缺少异常处理,而这肯定是应该加上的。尤其是当从远程 RSS 聚合摘要文件获取数据并加载到 XmlDocument 对象时,应该加上异常处理。因为远程的文件可能不存在或者格式不正确。
还有很多增强功能可以轻松地加入到这个在线新闻聚合器。一个明显的功能是需要一个管理页面来允许用户添加,删除和编辑他们现在的聚合摘要。还有,如果能允许用户自定义分类 ,将他们的聚合摘要按类别放在一起就更好了。另外,现在的用户界面还是比较粗糙的,但是通过增加一些 XSLT 样式表生成的 HTML 代码或者在几个框架里面增加一些样式表就可以很容易地美化一下界面。最后,在html标签里面加一些<meta>元素,可以让右上部框架定时地去刷新,使得用户不用自己手工去刷新页面就可以看到最新的新闻项目。
注解 (2003年8月4日): 在这篇文章发布以后,一些读者用 Email 告诉通知我在显示特定 RSS 聚合项的 <description> 元素时,有两个潜在的问题:
1、Disable-output-encoding 属性,这个属性用在 <xsl:value-of> 元素中,但是并不是所有的 XSLT解析器都实现了这个功能。.NET XSLT 解析器支持 disable-output-encoding,但是还是要 注意一下,因为读者可能试图将这个应用程序移植到其它平台。
2、<description> 元素的 HTML 内容是被原封不动地输出的。但是,这些 HTML 内容可能包含恶意代码,比如 <script> 或者 <embed> 代码块。理想情况下,这些代码应该被剔除掉。为了清除掉这些有潜在危险的代码,可能需要用到一些扩展函数(参见 Extending XSLT with JScript, C#, and Visual Basic .NET)。想查看从 RSS 聚合 摘要剔除 HTML 内容的更多信息,可以参见’’Dive Into Mark’’ 日志.
总结
在本文中,我们不仅讲到如何创建一个聚合引擎,还创建了一个在线新闻聚合器。在建立这两个应用程序时,我们都采用了在 ASP.NET 页面显示 XML 数据的技术。在聚合引擎里面,我们使用了 Repeater 控件以 XML格式来显示数据库中的数据。而在新闻聚合器里面,我们使用了 XML Web 控件和 XSLT 样式表。
我邀请你下载本文的在线新闻聚合器,然后根据你的需要来增强它。如果有任何关于这个应用程序或者这篇文章讨论的概念方面的问题,随时恭候你的 EMail。我的 EMail mitchell@4guysfromrolla.com.

 QQ:2693987339(点击联系)购买教程光盘
QQ:2693987339(点击联系)购买教程光盘

















